

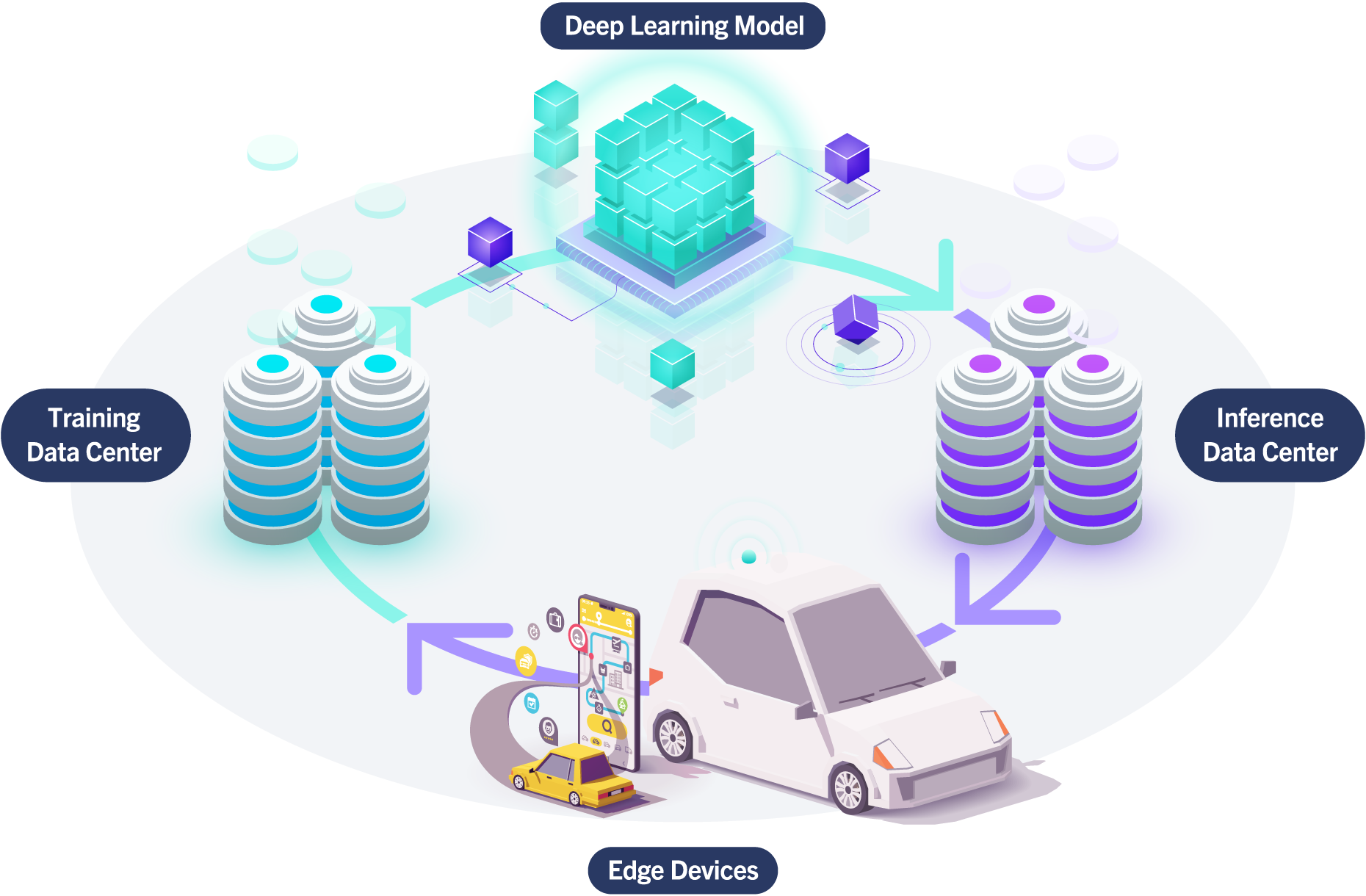






Accelerate Deep Learning Initiatives
NVIDIA DGX B300
The universal system for all AI workloads, offering unprecedented compute, performance, and flexibility. NVIDIA's purpose-built system powers enterprise AI across the world. Leverage 72 PetaFLOPS of AI Performance with NVIDIA DGX B300, the foundation and building block of AI Factories.
Inquire about our NVIDIA DGX EDU discounts.




